
稀疏矩阵
在矩阵中,若数值为0的元素数目远远多于非0元素的数目时,则称该矩阵为稀疏矩阵。与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。
注:压缩存储的矩阵可以分为特殊矩阵和稀疏矩阵。对于那些具有相同元素或零元素在矩阵中分布具有一定规律的矩阵,被称之为特殊矩阵。对于那些零元素数据远远多于非零元素数目,并且非零元素的分布没有规律的矩阵称之为稀疏矩阵。
稀疏矩阵的特性
稀疏矩阵其非零元素的个数远远小于零元素的个数,而且这些非零元素的分布也没有规律。
稀疏因子是用于描述稀疏矩阵的非零元素的比例情况。设一个 n*m 的稀疏矩阵 A 中有 t 个非零元素,则稀疏因子δ 的计算公式:$δ=t/mn$ (当这个值小于等于0.05时,可以认为是稀疏矩阵)*
稀疏矩阵的压缩存储
存储矩阵的一般方法是采用二维数组,其优点是可以随机地访问每一个元素,因而能够较容易地实现矩阵的各种运算,如转置运算、加法运算、乘法运算等。但对于稀疏矩阵来说,采用二维数组的存储方法既浪费大量的存储单元用来存放零元素,又要在运算中花费大量的时间来进行零元素的无效计算,显然不科学。所以必须考虑对稀疏矩阵进行压缩存储。
对稀疏矩阵进行压缩存储的一种较好的方法是:只存储在矩阵中极少数的非零元素,为此必须对每一个非零元素,保存它的下标和值。可以采用一个三元组Trituple<row,column,value>来唯一地确定一个矩阵元素。因此,稀疏矩阵需要使用一个三元组数组(亦称为三元组表)来表示。
常见的压缩存储方式有压缩行和压缩列。
对于如下矩阵
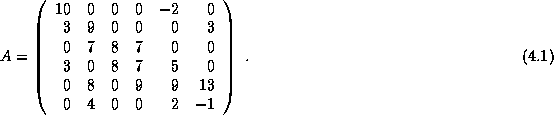
以三元组的方式(假设索引从1开始)为:
(row_index,col_index,value)
|
|
Compressed Row Storage (CRS) 压缩行存储
压缩行和列存储格式是最通用的:它们不对矩阵的稀疏性结构做出假设,并且不存储任何不必要的元素。 但是,效率不高,需要对矩阵向量积或预处理器求解中的每个标量运算进行间接寻址步骤。
CSR矩阵格式通过用三个一维的数组来存储一个m×n的矩阵M。定义nnz(Num-non-zero)为矩阵M中非0元素的个数。
val[]: 存储非 0 元素,长度为 nnz。col_ind[]:存储 val 中元素的列索引,nnz。row_ptr[]:存储每一行中第一个非零元素在 val 中的下标,长度为 m+1,其中 $row_ptr[m+1] = nnz+1$ 。这里即将行元素索引压缩了。
我们只需要 $2*nnz+m+1$的空间去存储矩阵。
|
|
Compressed Column Storage (CCS) 压缩列存储
|
|
LibRec 实现
由于推荐系统场景中,用户物品的行为矩阵是一个稀疏矩阵,LibRec 2.0 中的 SparseMatrix.java类 实现了这一数据结构。其同时实现了 CRS 与 CCS 压缩存储。
我们先查看 LibRec 如何读取输入的用户评分/行为矩阵。以 TextDataConvertor.java为例,readData()函数实现了数据读取,存入 SparseMatrx。主要查看以下部分。
|
|
我们通过构造器来查看如何进行稀疏矩阵构建。
|
|
以设置矩阵非0值与通过行列索引查找 rowData 的相应索引位置
|
|
查找稀疏矩阵中的对应元素
|
|
参考
Compressed Column Storage (CCS)
http://westerly-lzh.github.io/cn/2014/12/Sparse-Matrix-Storage-Style/